While working on a new project I decided to use Entity Framework core as the project had a very simple setup and didn’t needed to complex Database settings or queries. A perfect use case to try out EF core.
Implementation was just a breeze while making use of the Repository pattern and the Unit Of Work pattern. Although the application hasn’t have a load of business logic. still I wanted to add Unit tests to validate the implemented logic.
In previous projects we used Moq to create mocks to support the NUnit test framework. For this project I decided to have a look at the Fake It Easy framework. The website promises:
Easier semantics: all fake objects are just that — fakes. Usage determines whether they’re mocks or stubs.
Context-aware fluent interface guides the developer
Easy to use and compatible with both C# and VB.Net.
And I must say, I had to dive in the documentation a few times but for the rest, it was quite simple to set up the mocks and implement the Unit tests.
Mocking DBSet
With the experience of previous projects I knew that mocking a DBSet needed some extra setup. As long as you don’t have to mock queries on the DBSet you’re fine with the default implementation but not if you want to test async queries asFirstOrDefaultAsync(), SingleOrDefaultAsync(). Those are only supported when running against an EF query. For EF 6 there is a very well worked out example (Testing with a mocking framework) on Microsoft Docs.
My first attempt was to use the demo code available for EF core to create the mock and try out if it would work for EF core. But instead of implementing Moq, I’ve used Fake It Easy. First you have to create a TestDbAsyncQueryProvider. I’ve copied the code from the demo on the docs page and noticed the IDbAsyncQueryProvider doesn’t exist any more. After some searching I found that it was renamed to IAsyncQueryProvider. I had to update a few implementations but got it building. The full implementation of the class:
But you also have to make some changes to setup of your mock of the DBSet:
If you now run your tests you will see they run successfully. If you are getting an error like below, make sure your set the mock of DBSet to implement IAsyncEnumerable<TEntity>
The source IQueryable doesn't implement IAsyncEnumerable{0}. Only sources that implement IAsyncEnumerable can be used for Entity Framework asynchronous operations.
Generic solution
Off course you don’t want to repeat all this setup every time you have to write tests for a repository. The solution is to create a helper class where you can define the Entity (and the context if you like) like I did in the class below:
Create Nuget package to reuse in other projects
As we are going to use EF Core in future projects, it would be a timesaver to add the generic implementation in a nuget package to reuse in the Unit tests. As I was looking into creating a package to publish on Nuget I found already a generic solution created by Roman Titov called MockQueryable that was published on Nuget.
The tooling in Visual Studio is great, you can easily deploy from Visual Studio to file, servers, Azure, Docker, … Deploying to Azure is as simple as downloading a publishing profile from the Azure portal and import it into Visual Studio.
There are more the enough resources on the web that give you excellent guidance on how this actually works and is out of scope of this blog post.
For one of the projects we are working on, we’ve created a middle tier for an existing REST service. Due to the lack of logging and being hosted on unreliable hardware we’ve decided to create our own REST service and host it on Azure. This will give us a 99% uptime and increased logging experience we’re we and the customer can benefit from. During the development fase we wanted automatic tests to check if our new middle tier is returning the same results as the original REST service.
Part of this test is the automatic deployment to Azure. The project itself is built on every check-in to our source control on our internal TeamCity build servers. If the build is successful we wanted to automatically deploy it to our Azure account. When the service will be used in production we want to deploy to a staging environment first and then promote it to the production environment, both hosted on Azure.
Existing resources
I was convinced it was an easy peasy task to deploy from Teamcity, we already use webdeploy to deploy our projects to internal IIS servers, changing that to Azure should be a walk in the park. As you can imagine, I wouldn’t take the time to write a blog post about is if it was just a 1, 2, 3 step process.
After some trail and error (a lot of error, most of them with general error messages…) and searching in log files it actually is not to hard to set up.
Step by step
Getting publishing credentials
First step would be to log in to the Azure portal to download the publishing profile. We are going to need the data that’s in that profile.
(Apparently it is not so clear to change your language in the Azure portal, the screenshot is from the Portal in Dutch, but the English version should look similar).
You can open the downloaded profile with any text editor as it is just XML. In the screenshot below you’ll find an example (I had to obfuscate some data)
The data you’ll need in the next steps (with off course the correct details):
publishUrl: YOUR_PROJECT.scm.azure-mobile.net:443
msdeploySite: YOUR_PROJECT_WEBSITE
userName: $USERNAME
userPWD: A_VERY_LONG_PASSWORD
Set up TeamCity
To set up a new project I refer to the TeamCity manual, we’ll focus on the actually steps to get the website deployed.
We first set up 2 simple build steps, one to install the Nuget packages and one to build our solution on Release configuration.
Simply add these steps and select your projects .sln file. We’ve installed Visual Studio 2017 SDK on our build agents but this should also be working on the 2013-2015 SDK.
Because we have a solution with multiple projects, we add an extra build step to just deploy the Web API (REST) service without interference from the other projects in this solution.
Add a new build step and choose for MSBUILD. Select the .csproj file from the correct project. The key to set up the webdeploy is to add the correct parameters to MSBUILD. In the command line parameters add the following parameters:
You’ll see the parameters hold the data we retrieved from the publishing profile. Just one note, I’ve put every parameter on a new line to be better readable. When adding these parameters be sure to avoid line break and extra spaces! I’ve spend more then one occasion bug hunting for a lost space or line break!
Be sure to enter the URL found in the publishing profile at the MsDeployServiceUrl parameter. It had got me confused because webdeploy to IIS uses a full URL like “https://YOUR_SERVER:8172/msdeploy.axd”. So lose the https and the axd reference and copy the correct value from the publishing profile.
You can now run your build on TeamCity and if everything goes well, your website or project should be automatically be deployed to Azure. You can add triggers to do this on each check-in or at a certain time daily.
Every developer can see the credentials
Depending off course on the user settings in TeamCity the credentials you have added in the parameters of the MSBUILD step are readable by every developer. This is off course especially for production environments not safe.
To avoid this security breach we can make use of Parameters in the Team City build server. Open up your build configuration and go to the tab Parameters and click the add new parameter button.
Add a new “configuration Parameter” with name “deployUser” and value “$USERNAME”.
To avoid that this parameter is visible, click the edit button and select in the popup for type “Password” and by display for “Hidden”. You can add a label and description but that’s not obligated.
By setting the type to password you avoid the parameter to be displayed in log files and setting screens. Click save twice and add an new parameter for the password with the name “deployPassword” and the correct value.
Now go back to our MSBUILD build step in TeamCity and alter the Command line parameters.
Alter the username to %deployUser% and the password to %deployPassword%. On build time TeamCity will insert the correct values. Colleague developers will only see the %% parameters in TeamCity.
Conclusion
It is actually not to hard to set up in TeamCity. The only problem is that the resources are not that clear when first looking for information. Little differences with using WebDeploy to IIS servers makes it error prone while setting up.
Once set up you can use the same solution for your staging, acceptance, test, production, … environments, just change the parameters.
It’s a fast moving world for software developers. New frameworks, functions, possibilities, are rising up almost every day. Although you can find many resources online in different formats (blogs, videos, live coding, …) it’s always an advantage to attend a conference where you can learn the new stuff and meet up with some of the leaders of the industry.
Until 2014 Microsoft organised an European Teched conference but decided to stop with the Teched at all (also the North America edition) and focus on their BUILD conference. Due to a lack of an European alternative we tried to get tickets for the BUILD conference in San Francisco this year but you have better luck trying to buy U2 tickets for a small venue. Luckily we noticed the DEVIntersections conference in Orlando that takes place only a 3 weeks after the BUILD conference and with an impressing line up of speakers.
Now the last day of the conference is arrived, is it time for a little wrap up. Please note, these are my personal findings not only about the technical items from the conference but also travel, stay, hotel, …
Long way from home
Not really a downside, but it’s reality that the travel from Belgium to Orlando takes a while. It’s not my first visit to the States so I did know what to expect. Due to the terrorist attacks on march 22 in Brussels our flight was diverted to Schiphol what led to some extra travelling. From the moment I’ve parked my car in Berchem till we entered the hotel a 20 hour trip was finished and has taken us from a train ride to Schiphol, an 8 hour flight to Atlanta, a 2 hour flight to Orlando and an 45 min taxi ride to the hotel.
Disney World
The conference takes place in one of the Disney World hotels, the Walt Disney World Swann and Dolphin. And the hotel is huge! You can’t compare with any hotel you find in Belgium (or the parts of Europe where I travelled before) and due to the Disney park, it houses a mix of different conference attendees (and yeah, you can pick the IT dudes out of the crowd ) and families ready for some days of Disney fun.
The room was fairly standard but clean and comfortable. A bit a pity of the view as we’re just above a roof of one of the adjusting buildings of the hotel. But once you step outside the room and start walking around you are directly in vacation atmosphere. You have the 5 different swimming pools, different hot tubs, 7 or 8 different restaurants in the hotel complex, the Disney Broadwalk around an artificial lake, boat trips from one side to the other, …
Fun for the first days, but after a while you have seen it all. Plans to go to downtown Orlando, we didn’t travel that far for just the Disney magic, weren’t realistic by the lack of fast public transportation and the cost for a taxi fair in combination with the time we could spend downtown after a day of conference.
DEVIntersections – the workshops
Next to the conference itself, they also organised 4 days of workshops and hands on labs the days before and after, where we registered for the 2 days pre work shops that are titled: ‘Making the Jump to ES6 and TypeScript’ and ‘Building Single Page Applications with Angular 2’.
I’ve only been looking into Angular (1.4) and Typescript shortly so the workshop was very interesting. Learned a lot about Typescript and how it can construct and organize your codebase on a much better way with a lot of advantages. Certain something to look further into.
After the first day of Typescript introduction, you notice on the second day how it perfects integrates with Angular 2! A lot of new stuff was thrown at us and it will take me some time to digest all that information but it’s a very good base to start building Angular 2 apps in the future.
Both work shops were presented by John Papa (John_Papa) and Dan Wahlin (DanWahlin), both experts in these matters. You could notice they worked together before as they seamlessly took over from each other and were joking around without falling into a comedy show.
Although it was announced as a “hands on” workshop, the “hands on” moments where few and maybe there should have been more time for the attendees for trail and error on their own machines, especially for an all day workshop.
Note to the organisation itself, if you ask attendees to bring there own device, please make sure there are power sockets for those people. More then half of the attendees ran out of battery before lunch and were unable to use their machines for the rest of the workshop. We were so wise to come early the second day and choose one of the few places where there was a power socket in reach.
DEVIntersections – the sessions
The conference content was of a very good level! Most of the speakers are the experts in their field and many Microsoft employees stood on stage. You could notice there were a lot more attendees then the first days during the workshops but still it wasn’t too busy. Not too much queues (except at the men’s rooms during breaks , the ladies still have a huge advantage on these IT events).
The first keynote was by Scott Guthrie (scottgu) and was a general overview about Azure and could be in my opinion a lot wider and a bit more developer focussed instead of the commercial tone. The videos shown were the same as shown on the build conference but that was to be expected.
The second keynote on the first day was from Scott Hanselman (shanselman). You can’t always predict what he’s going to talk about, but you can at least be sure it’s a good mix of technical innovations an a lot of humour. I’ve also went to the other session that was presented by him and on both occasions it was top notch entertainment with a lot of new exiting things that are coming our way. He’s not afraid to point out where there are still some improvement opportunities for Microsoft but is straight on about where the the different teams of Microsoft are focussing on at the moment. He managed to install the latest development version of Visual Studio on one of the attendees his laptop, who had surprisingly no Visual Studio instance installed??? While trying to connect the laptop, bringing in the technical fellows, he managed to bring that without boring for 1 second.
The last day of the conference was lacking good interesting sessions for me what gave the feeling all was said during the first days. Except some 3rd party frameworks like NodeJS and ReactJS there were not many full developer sessions that were based on Microsoft technology except then the keynote about Sharepoint. (what gave me the time to write this post ).
But overall good content, excellent speakers and we picked up a lot of new things. If I find the time, I make a follow up post.
DEVIntersections – social
Maybe I’m a bit spoiled by the Tech Ed conferences and the Xamarin Evolve conference I attended in November 2014 but I missed the social parts that makes a good conference a wow conference.
For one, the sponsors expo was limited. With 10 company stands there was not so much to see or to speak about. The boots were small as the expo took place in the hallway between the different rooms.
Ok, a bit childish but there were not so many goodies to find. On previous occasions I’ve been able to make my son very happy with a bunch of goodies that I’ve taken with me from the exhibitors expo.
There were 2 evening gatherings (if I didn’t miss one, but saw no other in the schedule or announcements). On Tuesday the opening of the partner expo with drinks and snacks. It’s a pity they just gave one coupon for a drink and not so many snacks. Because there was only one drink included, the reception was over quite early as everybody went to somewhere else.
I didn’t went to the after dark sessions on Wednesday but the general feedback from the people I spoke, wasn’t that overwhelming and many bailed out during the session.
As other conferences were held in the same hotel complex, you could see the difference. We’ve saw at least 3 beach parties with open bar, music, a lot of people and seemed to be a good atmosphere. It would have been great if DEVIntersections had organised one of those.
DEVIntersections – General
Overall it is a good conference with some grow opportunities on their way. Off course Rome wasn’t build in one day, and DEVIntersections is a very young conference. I’ve enjoyed my stay in Florida and learned a lot of new interesting stuff. I’m a big fan on how Microsoft is proceeding and it will be challenging times for aswell Microsoft as the developers using their stack to create excellent apps on different platfoms, mobile, web, desktop, cloud, IoT, …
For a project we’re currently working on we needed to be able to search on different fields that are shown to the end user. We didn’t want to rely fully on the SQL server Full Text Search capabilities. Luckily I knew the Lucene.NET engine from some previous work with the Umbraco CMS.
We just wanted to receive from our search engine the ID’s of the objects where the search term in was found rather then complete objects. When working with a database it just doesn’t feel right to store all your data on 2 different places (the database and the search index store). We only wanted to add the fields where we would search on to the search index and let Lucene decide the match, afterwards we’ll pull the objects from the database using Entity Framework.
Setting up Lucene.NET
Setting up Lucene.Net is not that difficult and you can find a lot of blog posts on how to use Lucene (like Introducing Lucene.NET on Code Project) and with a Nuget package available it’s easy to add the engine to your project.
I’ve followed a few of those blog posts I could find. Off course these posts give you a starting point and for the simplicity all code is written in one or two classes. After the first implementation I started with some refactoring’s and decided it would be easier for future implementations if I created my own search DLL or package.
At the bottom you’ll find the link to the Github repository where you can browse and download the package.
Documents
If you want to be able to search in Lucene you’ll have to add the parameter to a Lucene document. To simplify the creation of such documents I’ve created an abstract class ADocument where you have to inherit from.
You’ll see that I’ve added the public property “Id” so that every class that will inherit should have that Id. In the setter of the ID you’ll see I add the field to the Lucene.Net Document with the AddParameterToDocument method.
Next to the private AddParameterToDocument method you’ll find two other methods, one with the possibility to store the parameter in the Lucene index and one to just analyze the parameter but not to store it in the Lucene index.
SearchField
You’ll see in the ADocument class that I’ve decorated the “Id” with the “SearchField” attribute. This attribute was created to simplify the search on multiple fields that you’ll see when implementing the BaseSearcher. You can find the implementation of this attribute below.
BaseSearch
Both the writer as the searcher have to have access to the index that is written to the local file system. To avoid multiple implementations (check if the directory exists, load a FSDirectory object, …) I’ve created a BaseSearch class. Not much to see in this class, just some basic settings of the folder where the index is stored.
BaseWriter
before we can search we’ll have to add some items into the search index off course. Following the DRY principle we’ve created a new abstract base class, the “BaseWriter”. In this class we added the methods to add and update new or existing item(s) of the type of ADocument. Next to adding and updating we added the corresponding delete methods. Because we delete everything based on the Id property of the ADocument implementation it’s important its value is always set in the deriving class.
NOTE: the log messages are added to be used with Log4Net.
BaseSearcher
Adding items to the Lucene index wasn’t that hard. When I first started to implement the search methods I wanted to be able to search on a specific property or on all properties available on that object.
To be able to search on all properties you’ll have to user a MultifieldQueryParser instead of the default QueryParser. But with the MultifieldQueryParser you have to enter all the fields where Lucene have to search on. I really didn’t wanted to have to implement the same search code for every type we have to add to the index.
We’ll no choice then to turn to reflection to fetch all the parameters. But the class could have more properties then the one we are searching on. To avoid these extra properties (and the errors because we’ll be searching on properties that are not indexed) I’ve added the SearchField attribute.
So the first thing we’ll do when searching is to fetch all properties from the class and add them in a list. By using the T parameter we can easily reuse the same method for different classes as long they inherit from ADocument.
With this list we can now implement the actual searching. If we search on a specific field we’ll use the default QueryParser and if we are searching on more then one field, the MultifieldQueryParser.
When you look into the code, you’ll see that even when searching on a specific field, there’s still a possibility that the MultiFieldQueryParser is used. I’ve added the option to search on multiple parameters in the Lucene index if they are related to each other.
For example: you have a registration number for each person that always starts with the year of registration, a number (sequence) and a suffix: 2014-0023-aaa. When you add this complete registration number to the index and you search on 2014 (without wildcards) the Lucene engine will return no results. To avoid that the end user have to use wildcards you can store the registration number in three different parts. But when you want to search on the field RegistrationNumber you’ll have to indicate that multiple fields have to be used.
Therefor can the SearchField parameter contain a array of strings that contain the other searchfields that have to be taken into account. (confused, see the TestApp project on github)
ParseQuery
The search term that the end user enters has to be translated to a Lucene.NET Query. There a re build in methods to convert a string to a Query object. Although the method can throw a ParseException if invalid characters are used. Therefor I added a private ParseQuery method to catch those exceptions and to filter out the invalid characters.
SearchResult
Because we only want to return the Ids of the objects we’re searching for we can use a generic SearchResult class to return the results. The amount of hits and the search term are added to the result to be shown in the UI.
Test application
The above classes (except a custom exception) are all the parts we need to start testing our search wrapper. On the Github repository you’ll find a TestApp project in the solution where the classes below are implemented.
Person
The example used is of a Person that will register for a service. For simplicity sake local classes are used as repository instead of a database but you’ll get the point.
We”’ll start with the Person class that is used in some application. All default stuff and an override for the ToString method to print out Person class.
PersonDocument
It are these Person classes we want to add to our search index. To add these we have to create a PersonDocument class that implements from our ADocument abstract class. We”’ll add all properties with private backing fields so we can call the ‘AddParameterToDocument’ methods. Next to adding the property to the index we’ll have to decorate the properties we want to search on. (See the RegistrationString property where we added multiple SearchFields)
At the bottom I added a operator method to cast the person object to a PersonDocument object so I don’t have to repeat the cast in the business logic.
PersonWriter
The PersonWriter class will be not that difficult to implement now our PersonDocument class is defined. We just have to add the add and update methods and the delete methods that will call the base class methods.
PersonSearcher
Also the PersonSearcher class will not be that difficult with the Search method implemented in the BaseSeacher class.
Program
In the program.cs file you’ll find the creation of the multiple Person objects an how they are added to the index. Underneath you’ll find the different search methods and their results.
Conclusion
Although Lucene.NET has far more options then showed here in this blog post, will the created wrapper at least give you the basic search possibilities. Off course can you extend the base classes to add more search options, index options etc.
With the basic settings in the Document class that inherits from ADocument you’ll avoid to create numerous searchers or indexers.
All source code can be found on GitHub and feel free to fork or download.
I saw a tweet from John Galloway (@jongalloway) coming by this evening that can interest any developer in the ASP.NET stack. It’s a draft of the features that Microsoft want to include in the next release of the stack.
There are no release dates and they do emphasize it’s a planning document but I like the way Microsoft is going with the open sourced ASP.NET stack.
For one of our projects where close to the first test release. While preparing the necessary documents (test overview, legal documents, bug report, …) I felt a bit ashamed to give the client a Word document to report bugs to us. For a software development company it’s a bit shameful to let the client fill out a paper, scan it, mail it and then have someone copy the document in our issue tracker.
While driving home I thought it couldn’t be that difficult to set up a small site where the client can report the bugs. But I didn’t want to create a new bug tracker nor give the client direct access to our issue tracker (JIRA from Confluence).
JIRA has a API that you can address to create and fetch issues from their tracker. But I didn’t want to spend a couple of hours implementing the REST service. (jeah, I know, lazy as hell)
Nuget to the rescue
When I got home, the first thing I checked was the nuget site to see if anyone had already created a package to communicate with the JIRA API. First thing that showed up in the search was Atlassian.SDK a complete package, even including a Linq Query implementation to search for issues created by Federico Silva Armas.
Great, let’s get started.
New MVC 4 web application
I fired up Visual Studio 2012 and choose a new MVC 4 Default application with Razor support. Opened up the Package Manager Console and ran the following command:
Add controller
I added a new controller in the controllers folder and named it HomeController. In the Index method I’ve added the call to JIRA to fetch all items from a certain filter.
The implementation is really simple, create a new Jira object with as parameters the URL to your JIRA instance, a username and a password. (in the constructor) In the Index method you then can call GetIssuesFromFilter and add the filtername as parameter. The advantage of using a filter is that you can always change this filter settings if you want to remove certain issues from the result without to change anything in your application.
You’ll need off course the user rights correctly set in JIRA to access the issues that are returned from the filter.
Add View
Next I created a new view under the Views – Home folder using the add view action after a right click on the folder. Create a strongly-typed view by selecting the Atlassian.Jira class as Model class.
Click Add and the view is created.
If you hit F5 now, your browser should open up and you get already the overview screen for all issues returned from the filter you have selected.
In 10 minutes I’ve created a working (but ugly) web application that can fetch all the tickets I wanted to show to the customer. Of course your view will need some tweaking to show the values of the issues you want to be shown.
Adding a new issue
Adding a new issue to JIRA is as simply. (You can check the complete code on Github). I give you a (very) short overview.
Create 2 new methods Create in the HomeController. The first one just returned the view, the second one add the HttpPost attribute and this will receive an Atlassion.Issue object with all the values. Pushing this to JIRA is as simple to create a new issue object from the jira object and fill up the values. Hit SaveChanges on the jira object and your issue is created.
On thing I had a problem with is the projetc name – key difference in the jira.CreateIssue() method. I first tried with the project name but I got some HTML 500 error returning. Although for fetching issues this worked fine but for creating issues you apparently have to gibe the project key instead of the project name.
Look and feel
Ok, we have a working application but the look and feel isn’t that, certainly not enough to send to an end user. I didn’t wanted to spend to much time on the look and feel and decided to use the Twitter Bootstrap.
Don’t start downloading the package from the Twitter Bootstrap website. Instead use the nuget package manager again. There is a Bootstrap for MVC 4 package that will add all necessary items to your solution.
Open up the Package Manager Console again and run the following command:
Add bootstrap to the bundles
To add the bootstrap files to your application we’ve to alter the style and script bundles that are in use. Open up the BundleConfig.cs class in the App_Start folder. There we can add the necessary files to the bundles.
Online 28 I changed the the Content/css bundle to include the bootstrap css instead of the default Site.Css. On line 21 I added a script bundle to include the bootstrap.js file.
Because I added a script bundle we’ll have to add this bundle in the _ Layout.cshtml view.
Just underneath the rendering of the jQuery bundle add the rendering of the bootstrap bundle. (at the bottom of the view.
Result
I was able to create an new interface for our client to report bugs in just an hour of two. (the above only took 30 min but I’ve added some extra logic to send emails and stuff). Off course it’s not correct to add all business logic in your controllers and to hard code some strings and stuff. For this small application it’s more then enough. Underneath the screenshots of the 2 pages (in Dutch).
Source code
You can find this project on Github, feel free to fork, comment, …
One note, to avoid adding my personal credentials to the project I’ve created an xml file that holds the credentials in the App_Data folder. When creating the Jira object I fetch the values from this file. For obvious reasons I added this file to the .gitignore so it wouldn’t be pushed to Github. The structure of the file:
For one of our projects we had to retrieve data from an external source and store them in a database. One of the requests from the client was to see the retrieved data in a graph. Furthermore, he wanted to see a live update every second of the retrieved data in that graph.
After some searching I found the OxyPlot library. This library can be used in WPF, Silverlight, Windows Forms and even in Windows Store apps. The are now working on a alpha release for Mono.
Although the package is already downloaded more then 10 000 times there are not so many blog posts to find about implementing the library.
Open op Visual Studio and start with creating a new WPF project. Choose a name and a location and hit ‘OK’.
After the project is created open up the Package Manager Console and type following commands at the prompt and hit enter (after every command):
Install-Package Oxyplot.Core
Install-Package Oxyplot.Wpf
You can of course use the Package Manager UI by right clicking References and choose Manage Nuget Packages and them that way.
Create the ViewModel
We’ll use the MVVM model (partial) to render the Graph on the screen. First step is to create the ViewModel for our MainWindow.xaml. Right click on the project and add a folder ViewModels. Right click the folder and add a class MainWindowModel.cs.
To use the MVVM model we need to make the class public and inherit the INotifyPropertyChanged interface.
NOTE: The OxyPlot WPF package doesn’t completely support the MVVM model. You can’t use only the OnPropertyChanged method to update the graph. You’ll still need the manually refresh the graph from the code behind class of the XAML page. I saw a post in the discussions on codeplex that they are looking to add complete MVVM model but are short of time at the moment. Maybe the next version will support it. To be complete I add the necessary steps to implement the MVVM model in this post.
After inheriting the interface we have to implement the PropertyChangedEventHandler event as shown below.
Now we can add some public properties that we’ll bind to in the XAML page. First create a PlotModel that’s part of the OxyPlot library. In the constructor we’ll initiate the PlotModel parameter. The setter will call the OnPropertyChanged method that will notify the view there is a change on the object that may have to be rendered.
Adding the graph to the page
We can now add the graph to the MainWindow.xaml page. Before we can add the graph we’ll need to add the namespace for the OxyPlot library (line 4). We’ll bind the PlotModel parameter to the PlotModel we’ve created in the view model.
Binding the model to the view
Last part for our setup is to bind the view model to the view. Because we don’t use any MVVM frameworks we’ll have to manually bind the model in the code behind of the MainWindow.xaml page.
Add a private property of our view model and initiate this property in the constructor. Point the DataContext to this property and we’re done.
If we hit F5 to run the application we’ll see an empty window opening. We have of course add some data to the PlotModel before the graph will be rendered.
Set up the Graph – PlotModel
Back to our view model to set up our view model. First start will be adding the axes for the graph so OxyPlot knows where to plot the points.
Create a new method SetUpModel in our view model class. In here we’ll define the legend of the graph (position, border, sire, …) and add 2 axis. A DateTimeAxis for our X-axis (we want to plot points in a line of time) and a ValuaAxis for our Y-axis.
The set up for the legend of the graph is self explanatory. At line 10 you’ll see the creation of the DateTimeAxis. We’ll choose the position of the axis, give it a name (Date) and a string format pattern how the date has to be displayed. Next to that we’ll add some parameters to show major and minor gridlines and the interval size. After creation we’ll add the axis to the PlotModel. The ValueAxis is similar initiated, only did we position the axis on the left side and tell the Axis to start at the value 0.
If we add a call to this method in the constructor of our view model and hit F5 again we’ll now see window opening that contains an empty graph.
The data
Now we have our graph and are ready to add some graph lines to the PlotModel. In this post we’ll add four different lines that will be plot.
To avoid complexity I added a class Data.cs where the data is hardcoded. In a real life application you’ll be implementing a database call or a service invocation or a web API request, …
The data I’ll receive will be a List<T> of a new simple class I’ve created: Measurement. This class has 3 public parameters: a DetectorId (long), a Value (int) and a DateTime (DateTime). I’ve added 4 different detectors that each have 10 measurements of a random value between 1 and 30.
Add the data to the PlotModel
In the view model we’ll create a new method LoadData where we’ll get the data and add some code to plot all point on the graph.
After fetching the data I’ll use the LINQ GroupBy expression to create a IEnumerable with as key the DetectorId and a collection of Value and Datetime as values. (line 5)
This will allow us to loop over the result and then add a LineSerie per Detector. In the setup of the LineSerie we’ll set some properties like colors and line thickness and the title. (line 9 till 18).
After we’ve created the LineSerie we can add the points to the LineSerie. We make use of the DateTimeAxis builtin funtion to convert a date to a double and add the value (line 20).
After we added the points to the LineSerie we’ll still have to add the LineSerie to the PlotModel. (line 21).
And that’s it. Hit F5 and you’ll see that are graph will be rendered and that per detector a line will appear plotting the random values between 1 and 30.
Updating the graph real-time
For the second question of our client we had to add real-time updates. For this demo I’ll add an new measurement to the graph every second. The OxyPlot library will make sure our graph will move along every time we’ll add a new measurement.
I’ve added a static method in the Data.cs class that will return a random value a second after the DateTime parameter that will be send along. In the view model I’ve created a private parameter DateTime parameter (lasUpdate) that will hold the moment we last updated the graph.
Update the view model
We’ll add a new method to the view model UpdateModel. This time we’ll make it public so it can be called from the view as shown in the next chapter.
In the UpdateModel method we’ll fetch the data from out Data.cs class and perform the same grouping action as in the LoadData method.
This will allow us to fetch the data per detector. After retrieving the correct LineSerie we can add the points like we did in the LoadData method.
Update from the view
We don’t want the update of the model to initiate before the previous is completely rendered to avoid an exception that we are modifying a list while rendering the graph. Therefor we make use of a CompositionTarget.Rendering event. This event will be fired every time the view is done rendering.
In the constructor of the MainWindow.xaml.cs class we’ll attach an eventhandler on the Rendering event.
In the event handler we’ll call the update method from the view model. After that call we’ll have to tell the PlotModel that there was an update and that he has to refresh the graph (line 14). (This is where OxyPlot drifts away from the MVVM model).
Avoid to many updates
The rendering event is ideal to avoid exceptions but you’ll see to many updates per second to keep the graph readable. We can solve this to add a StopWatch in the code behind and only trigger the update when the last update is at least a second ago.
After adding the StopWatch we’ll see that every (for this demo 5 seconds) a new point is added to the graph.
Source code
As you can see, with OxyPlot you don’t need to write to many code to create real time updating charts.
OxyPlot has many more options and graph styles, they have provided a demo page where a variety of graphs are rendered in Silverlight. You can copy the source code with the keyboard combination Ctrl+Alt+C. If you want to copy the properties use Ctrl+Alt+R.
The source code of this post can you find on Github. Feel free to fork, download, …
For one of our company websites we got the question from HR to implement a chatbox on the website so interested candidates could contact them in an easy way. After comparing a few open source alternatives we decided to build our own using the just released SignalR framework.
Everything worked fine on our development server where we’re running a backup of the production Umbraco website. Our dev team could easily create the chatbox and sooner as expected we had a working chatbox to present to HR.
Moving changes to staging
Like all our development projects we work in different steps. Development on the local machine or development server, client tests on the staging machine. This way we remove the risk that some developers test come in the way of our clients testing.
For this implementation the client is our own HR department, still we follow the same development guidelines to avoid test data on the acceptance (staging) environment.
Extension methods missing
After copying all DLL’s and usercontrols to the staging environment we noticed that all of our Macros in Razor where failing. Suddenly the ‘umbraco.MacroEngines.DynamicNodeList‘ was missing the extension methods like ‘First’ and ‘FirstOrDefault’.
Start debugging
First reaction was of course to delete all the DLL’s we’ve altered for this last release and to reinstate the old DLL’s. Still we faced the same problem.
Back to start, we took a new backup from the production server and started the deploy again. There we noticed we overwritten a third party DLL ‘Newtonsoft.Json.dll’, a well known library for Json conversions created by James Newton-King. More information on his website.
We skipped the replacement of the DLL and all of our Razor scripts we’re working like before. Problem solved (we thought).
SignalR failed to work
After the re-deploy of our chatbox DLL’s and usercontrols we couldn’t get the chatbox to work. It seemed the SignalR hub was missing to contact the server to register a chat user. A check with Firebug reveled the hub couldn’t be loaded because a DLL reference couldn’t find the correct version of the DLL. Of course the ‘Newtonsoft.Json.dll’ was playing up again.
Some more debugging
No problem, we find out where Umbraco references the DLL and update it to the latest version and rebuild the Umbraco DLL and we’re good to go. Wrong, we checked the source of the 4.7.0 version that was available on codeplex but no sign of ‘Newtonsoft.Json.dll’.
Then it had to be one of our own projects referencing the DLL? No, none of our own project had a reference to the ‘Newtonsoft.Json.dll’.
I loaded the project on disk, configured it in IIS and attached the Visual Studio debugger. In the Debug menu –> windows –> Modules component I could find the ‘Newtonsoft.Json.dll’ reference but no way to find out witch component was responsible for loading the DLL.
Some more (manual) debugging
As I couldn’t find a way to find out who was responsible for loading the DLL I had only one option left.
I took a look at the download at codeplex and removed all DLL’s that were not in the original download. Of course some other problems showed up as all custom created usercontrols failed to load but the Razor Extension methods worked and I could start a tedious process of adding DLL’s to the bin folder with my Visual Studio debugger attached and to reload the site every time.
Found the problem
When I copied the ‘Twitterizer2.dll’ back into the bin folder the Razor scripts failed again. I finally found the source of the problem. After a quick look at the Github repository of the Twitterizer project I found the Newtonsoft references and the different versions in the packages folder.
Resolving the problem
I did found the problem but we wanted to keep the Twitter possibilities that we had implemented before so we needed the Twitterizer2 DLL.I forked the project on Github and cloned the project locally.
After updating the package to the latest version (the same our SignalR implementation was using) I’ve rebuilded the DLL and copied it to the Umbraco bin folder. Finally we had our Razor scripts working and our chatbox was responding!
It took me half a day of debugging before I did found the problem. If anyone has a good way to find out witch component loads a certain DLL, let me know in the comments or by a tweet, …
Umbraco had a rough year, is the least we can say . After working on version 5 from the bottom up for almost 2 years they decided beginning 2012 to stop the version 5 with reason. Although I understand the reasons I’m very glad I didn’t had put any effort yet in the V5.
Umbraco is an Open Source ASP.NET Content Management System that gives the developer a lot of freedom without interfering with the generated HTML, CSS and javascript. It has a steep learning curve but when you start to find your way into it, it gives you a lot of freedom.
At my company we used the 4.7 version to create the company websites (abc-groep.be). In that version we could only use Webforms user controls to incorporate our own business logic. As I’m a big fan of MVC this stopped me to use the CMS for personal projects. The V5 version was the big promise to use MVC in Umbraco (it was actually build on MVC). Lucky for me the Umbraco developers have taken into account that MVC is a big deal for developers and while the V5 was dead the V4 version branch was enriched with MVC.
In this post we’ll look into how you can use your own MVC controllers and views to create front end pages in an Umbraco installation.
Installing Umbraco in new web project
Let’s startup Visual Studio and create a new blank web project. Give it a name (here I used UmbracoMVCDemo) and click create. You’ll see that VS only creates an empty project with just 1 file, the web.config.
After creating the project we’ll add Umbraco by Nuget. Open the Package Console Manager and type “PM> Install-Package UmbracoCms” and hit enter. You’ll see the installation of a couple of dependencies passing by and you should see “Successfully added ‘UmbracoCms 4.11.1’ to UmbracoMVCDemo.”. If you hit F5 you’re browser should fire up and show the installation page of your local Umbraco CMS.
Folow the instructions to create your database (MS SQL Server, MS SQL Express Edition, MYSQL and) Microsoft SQL CE 4 database. Choose an administrator user and choose to have no template installed. (if you want you can install these later on).
After installation go to http://localhost:53998/umbraco/login.aspx (choose the correct port as configured in IIS Express or IIS). Log in with your just created administrator and you should see an empty website.
We then only have to specify we want to use MVC for our views. Open up the Umbraco.Settings.config file in the config folder under the root. Find and alter the next setting:
We start by adding a new project in our solution with a right click on the solution and choose Add – New Project
Choose a new ASP.NET MVC 3 Web Application and give it a name (in this demo UmbracoMVCDemo.FrontEnd).
In the next dialog choose for an internet application with Razor as View engine. We will need to have the Umbraco core libraries that we can add with Nuget. Open up the Package manager Console and type “Install-Package UmbracoCms.Core”, hit enter and wait for the “Successfully added ‘UmbracoCms.Core 4.11.1’ to UmbracoMVCDemo.FrontEnd.” message.
Create new controller
Add a new controller by right clicking the controllers folder and choose for Add – New Controller. Name it DemoController and choose for the Empty controller template.
The controller needs to inhered from the Umbraco.Web.Mvc.RenderMvcController controller instead of the default ASP.NET Controller class. Next to that we’ll have to override the default Index Action method. We need to add a view for the Index action and add some test text in the view.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Web.Mvc;
using Umbraco.Web.Models;
namespace UmbracoMVCDemo.FrontEnd.Controllers
{
public class DemoController : Umbraco.Web.Mvc.RenderMvcController
{
//
// GET: /Demo/
public override ActionResult Index(RenderModel model)
{
//Do some stuff here, then return the base method
return base.Index(model);
}
}
}
@{
ViewBag.Title = "Index";
}</pre>
<h2>Index</h2>
<pre>
This is our own Demo controller and View.
And that’s it, we’re ready to build. After building our Frontend project we’ll have to copy the generated UmbracoMVCDemo.FrontEnd.dll from the bin folder to the bin folder of our Umbraco installation. Next to the DLL we have to copy the Index.cshtml view from the views/Demo directory to the Umbraco installation views subfolder.
Configuring Umbraco for our DemoController
Umbraco uses a technique called ‘Hijacking routes’ to allow custom controllers. Basically will Umbraco for every Document Type check if he can find a controller that inhered the MVCRenderController and has the same name as the document type. If they can find a controller they will execute the overridden Index Action.
Open up your Umbraco interface in a browser window and click on settings. Right click on Document Types and choose Create. Type Demo and uncheck “Create matching template”. That’s all configuration that has to be done.
Go to the content section and right click on Content and choose Create. Select the Demo document type and name it Demo. After the entry is created click on the ‘save and publish’ button on top of the entry. Open up a new browser tab and go to http://localhost:53998/Demo (change the port to the port in your IIS or IIS Express settings) and you’ll see our test text appearing.
Using own models, …
At our.umbraco.org you’ll can find a lot of information on how to use your own custom models, bypass the Umbraco pipeline with your own routes, use templates to access different actions, ….
Automate the copy process
The copy action of the dll and your views can get a bit tedious after some time (in my case after the first time) but you can use after build events to automate this process. Open up the properties of the FrontEnd project and select the Buils events tab.
We saw before that we had to copy the Index.cshtml view from our Frontend project to our Umbraco installation root – Views subfolder. Especially if you want to use multiple actions in a controller the Umbraco Views folder gets messy. I’m more a fan of a folder per controller with in there the views for that controller.
That’s possible but there is a catch. The Umbraco engine checks if the view is present in the Views folder before allowing the request to use your controller. If the view is missing an empty page is returned. But if we add a Demo folder and add our index.cshtml view in there we’ll see that that view will be used before the view in the root views folder. (This seems to be intended and default ASP.NET MVC behavior)
Therefor we only need a placeholder view in the basic views folder. This can be an empty view or just add a text that refers to the correct folder. And we can then create a Demo subfolder and add the correct views in that Demo folder.
The post build action will also copy the views to the correct subfolder instead of the root views folder.
Second part to be careful with is when creating multiple controllers there will be multiple Index.cshtml views what will give problems in the root views folder. I can strongly recommend creating a second action with an unique name so you can use templates with a unique name for every controller.
In the last post (Synchronizing recipients with MailChimp lists) we’ve seen how we can fetch the mists that are configured in MailChimp. In this part we’ll add subscribers to the mist and get the chance to unsubscribe users from the same list.
Adding a contact class
If we want to add contacts to our list we’ll need to create new views and alter the home controller in our demo project. In our model folder we’ll add a new class, Contact.
using System;
using System.ComponentModel.DataAnnotations;
using DataAnnotationsExtensions;
namespace MailChimpAPIDemo.Models
{
public class Contact
{
[Required]
public string FirstName { get; set; }
[Required]
public string LastName { get; set; }
[Required]
[Email]
public string EmailAddress { get; set; }
public DateTime? BirthDate { get; set; }
}
}
You can see I’ve added 4 parameters, first name, last name, email address and birthdate. I’ve added the ‘Required’ annotation to the 3 required parameters. For the email address I’ve added the ‘Email’ annotation. This attribute is not in the default Annotations class but can be quickly added by adding the ‘DataAnnotationsExtensions’ package from Nuget. Open the Nuget Manager Console and type the following command.
PM> install-package DataAnnotationsExtensions
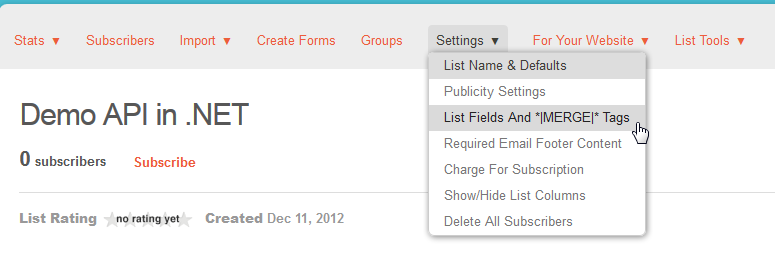
New lists in MailChimp have default only one required attribute and that’s the email address. You can alter the attributes you want to make required r you can add your own attributes by the web interface. Open up the list you want to alter and choose for ‘Settings – List Field and *|MERGE|* tags’
Then you can alter the field as you like. I’ve added the Birthday field and made the first and last name required for our demo list.
Adding the action and creating the view
Now that we have our Contact class we can add an Action in our controller. We add the ‘AddContact’ action twice. Once to deliver the view and one to retrieve the POST information.
using System.Collections.Generic;
using System.Linq;
using System.Web.Mvc;
using PerceptiveMCAPI;
namespace MailChimpAPIDemo.Controllers
{
public class HomeController : Controller
{
public ActionResult Index()
{
ViewBag.Message = "Modify this template to jump-start your ASP.NET MVC application.";
var returnValue = new List();
var lists = new PerceptiveMCAPI.Methods.lists();
var input = new PerceptiveMCAPI.Types.listsInput();
PerceptiveMCAPI.Types.listsOutput output = lists.Execute(input);
if (output != null && output.result.Any())
{
foreach (var listsResult in output.result)
{
returnValue.Add(new McList()
{
ListId = listsResult.id,
ListName = listsResult.name,
MemberCount = listsResult.member_count,
UnsubscribeCount = listsResult.unsubscribe_count
});
}
}
return View(returnValue);
}
public ActionResult AddContact(string listId)
{
return View();
}
[HttpPost]
public ActionResult AddContact(string listId, Models.Contact contact)
{
return RedirectToAction("Index");
}
}
public class McList
{
public string ListId { get; set; }
public string ListName { get; set; }
public int MemberCount { get; set; }
public int UnsubscribeCount { get; set; }
}
}
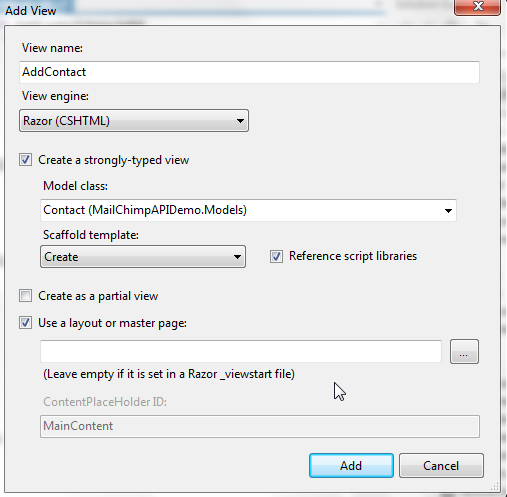
In the second action we will add the code to add the contact to the MailChimp list. First we’ll have to add the view to enter the contact’s details. Right click on the first ‘AddContact’ method and choose for ‘Add View’. (Don’t forget to build the application first so the new Contact class can be found)
Click ‘Add’ and you’ll see a new view get generated in the ‘Views\Home’ directory. We’ll still have to create a link in the ‘Index’ view to go to the new created ‘AddContact’ view. Because we need the list id we’ll add the link in the table where all lists are listed.
You’ll see the new table cell with the Html helper creating a link to the ‘AddContact’ action.
Implementing the POST action
Now we have a working view to add contacts we can implement the wrapper class in the POST action in the ‘HomeController’. In the previous blog post I’ve wrote down the workflow that is used for every API call.
The same workflow is used for every API call:
Create the correct main object from the Methods namespace
Create the correct input type object from the Types namespace
Call Execute on the main object
Catch the result in the correct output type object from the Types namespace
We start with creating a PerceptiveMCAPI.Methods.listSubscribe object and we’ll create a PerceptiveMCAPI.Types.listSubscribeInput object that this time will contain a few parameters. Every input class has a sub class ‘parms’ where the necessary parameters can be entered. Here we will add the email address of the contact that MailChimp will use as a primary key and the id of the list where we want to add the contact to.
[HttpPost]
public ActionResult AddContact(string listId, Models.Contact contact)
{
var subscribe = new PerceptiveMCAPI.Methods.listSubscribe();
var input = new PerceptiveMCAPI.Types.listSubscribeInput()
{
parms = new PerceptiveMCAPI.Types.listSubscribeParms()
{
email_address = contact.EmailAddress,
double_optin = false,
replace_interests = false,
send_welcome = false,
update_existing = true,
merge_vars = new Dictionary<string, object>(),
id = listId
}
};
return RedirectToAction("Index");
}
}
Of course we want to add the other values of the contact like first and last name. In the PerceptiveMCAPI.Types.listSubscribeParms class we already implemented the ‘merge_vars Dictionary’. In this dictionary we can add the other values.
[HttpPost]
public ActionResult AddContact(string listId, Models.Contact contact)
{
var subscribe = new PerceptiveMCAPI.Methods.listSubscribe();
var input = new PerceptiveMCAPI.Types.listSubscribeInput()
{
parms = new PerceptiveMCAPI.Types.listSubscribeParms()
{
email_address = contact.EmailAddress,
double_optin = false,
replace_interests = false,
send_welcome = false,
update_existing = true,
merge_vars = new Dictionary<string, object>(),
id = listId
}
};
input.parms.merge_vars.Add("FNAME", contact.FirstName);
input.parms.merge_vars.Add("LNAME", contact.LastName);
input.parms.merge_vars.Add("BIRTHDAY", contact.BirthDate);
return RedirectToAction("Index");
}
}
After we added all parameters we can invoke the ‘Execute’ method and catch the result in the output class. This class will only contain a bool value (result) if the API call succeeded or not. If it didn’t succeeded we can check the ‘api_ErrorMessages’ parameter of the output object. After the contact is added we’ll send the user back to the lists overview page.
Testing time
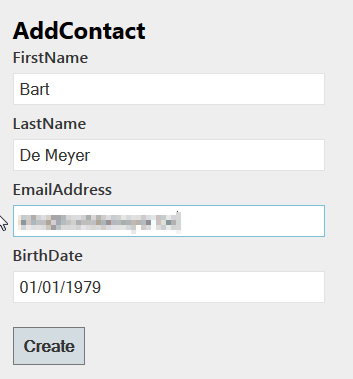
Time to test if our code is working. First of all we’ll run the application and go to the AddContact view by browsing first to the Index view.
After we click create will be redirected to our Index page where we’ll see the list now contains 1 member.
If we check in the MailChimp interface we’ll see the contact we’ve added by the API call.
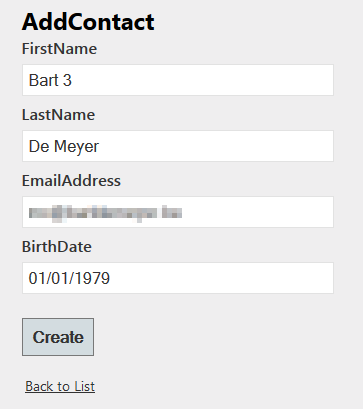
One problem that we see here is that the Birthday is not filled out in this overview. First mistake I’ve made is to add the merge parameter without testing if the nullable DateTime has a value. If we check the API documentation we’ll see that we have to send a date value as ‘YYYY-MM-DD’ and not the European format we’ve used.




























 Then you can alter the field as you like. I’ve added the Birthday field and made the first and last name required for our demo list.
Then you can alter the field as you like. I’ve added the Birthday field and made the first and last name required for our demo list.

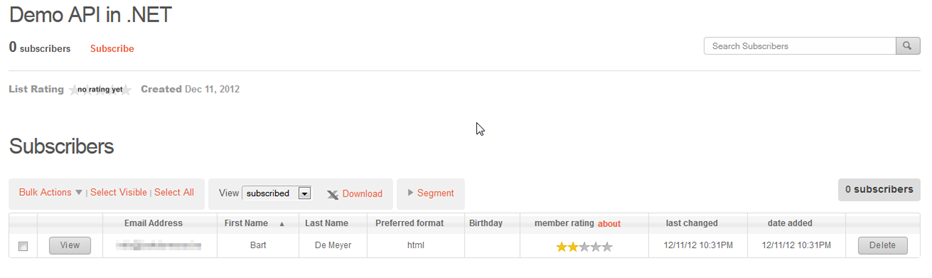 One problem that we see here is that the Birthday is not filled out in this overview. First mistake I’ve made is to add the merge parameter without testing if the nullable DateTime has a value. If we check the API documentation we’ll see that we have to send a date value as ‘YYYY-MM-DD’ and not the European format we’ve used.
One problem that we see here is that the Birthday is not filled out in this overview. First mistake I’ve made is to add the merge parameter without testing if the nullable DateTime has a value. If we check the API documentation we’ll see that we have to send a date value as ‘YYYY-MM-DD’ and not the European format we’ve used.